thesis
Design Space Exploration
CMPEN 431 • Spring 2025

Introduction
Different processors are architected with different design goals, some optimize for performance, others aim for efficiency, costs, area, or even combinations of these factors. Achieving these set goals require exploring multidimensional spaces of core microarchitecture, memory hierarchies, and cache configurations. This paper delivers a heuristic proposal to find high performing configurations under four different optimizations: Energy savings (EDP), Energy efficiency per area (EDAP), Performance sensitive (ED2P), and a balance of all (ED2AP).
With a total 18 different dimensions with up to 10 indices per dimension, finding the optimal configurations would be near impossible. Therefore I designed a search algorithm that uniquely adapts for each of the different optimizations. The following sections explore more on the design space, development of heuristic strategies, results, and a final analysis.
Design Space
To make full use of the limited evaluations, the validation function is crucial for ensuring that only architecturally valid configurations are considered, allowing the algorithm to prioritize meaningful design points. To simplify the implementation, I first decoded the encoded index values into corresponding microarchitectural parameters, to enforce classes of constraints: cardinality, structural, and realism checks. Cardinality checks ensured each dimension was within its allowed minimum to maximum range. Structural constraints verified compatibility with dependent dimensions, for example L2 < L1D + L1I and L2 block size < 2 × L1 block size. Realism checks filtered out inefficient designs like mismatched cache latencies, bottleneck scenarios like width > 2 × fetch speed, and other unrealistic HW constraints.
Now, after filtering out invalid configurations, the next step is to narrow down configurations toward individual optimizations. Since exhaustively iterating through each possible configuration is infeasible especially under a 1000 evaluation limit, I narrowed it down by targeting heuristics that exploit architectural characteristics for each optimization: EDP, EDAP, ED2P, and ED2AP.
EDP, which emphasizes efficiency, naturally led me to exploit simplicity (narrow, in order, minimal HW). As supported by lectures and energy tables in prompt, narrow in order processors consume significantly less energy per cycle. For example, the narrowest in order pipeline only consumes 8 pJ, whereas the widest out of order processors consume 27 pJ. Similarly smaller HW, like cache at 8 KB only use 20 pJ at 0.125 mW while main memory consumes 20 nJ at 512 mW per access.
EDAP, which emphasizes area, led me to exploit low footprint configurations that still look at energy and delay. I primarily selected an in order narrow pipeline since this significantly reduces area overhead. Additionally to what was learnt in class, the in order pipelines scale at width2 / 2 mm2, while out of order pipelines begin at 4 mm2 and scales exponentially.
ED2P, which emphasizes performance, led me to prioritize wide pipelines with fast fetch speeds and out of order execution. The performance table shows how in order processors take less time per clock cycle than dynamic with the same fetch width, but as learnt in class, out of order processors exploit ILP more aggressively and though there is a 5–10 ps increase, the processors can retire more instructions per cycle since it reduces pipeline stalls and hazards. Since ED2P enforces delay exponentially, improving IPC is more impactful than only saving a few picoseconds of cycle time.
ED2AP, which is a mix of all the previous objectives would require a hybrid approach. Since all components dominate, exploring a wide range of configurations that balance performance, efficiency, and area without sacrificing any single metric.
Iterations of Heuristic
Iteration 1 – Greedy Search
My first approach was a greedy, sequential approach where I initialized all dimensions to index 0, then incrementally and greedily selected space one dimension at a time. For example, in the first dimension (width), I tested all indices and locked in the index with better results. This continued for all dimensions, narrowing down to a “greedy” configuration. However, after testing, this was extremely exhaustive and I came to realize that I would be leaving many great configurations out simply due to a greedy early stage decision.
Iteration 2 – Neighbor Search
To fix the problem of bad early stage decisions and to explore more diversely, I switched to a more fair strategy that gave each dimension a chance. For each of the dimensions, I would increment its index and enclose it by modulating the valid choices:
configuration[dimI] = (configuration[dimI] + 1) % validChoicesThis generates a new “neighbor” of the previous iteration changing a single dimension, so over many configurations, it improves the diversity of the search with better results. However, I noticed when running, that there would be invalid configurations which would stall progress, therefore to fix this, iteration 3 introduced an embedded validator.
Iteration 3 – Retrieval Configuration
This iteration introduced an embedded validating checker to help reduce stalls. I would invoke the validateConfiguration() and if it returned 0, I would know that the configuration curated in iteration 2 failed and I would return a retreated configuration using a completely random configuration which I know would be less exhaustive on the system. While the 431projectUtils.cpp already rejects invalid configurations before finalizing them, my embedded validating checker would act earlier in the process by reducing redundant attempts within the proposal function.
Iteration 4 – Optimization based filtering
To individually exploit each of the four optimizations instead of treating all dimensions equally, I tuned specific dimensions to take advantage of architectural characteristics that aligned with the selected optimized goal.
For ED2P, I biased the configuration for high throughput, so large width, high fetch speed, and out of order execution. This aligned with the optimization with an emphasis on delay/performance rather than power. For EDP, I emphasized on the configuration to bias toward the lower half of the index space in each of the dimensions. This heuristic exploited simpler, more efficient hardware such as narrow in order processors and minimized HW. For EDAP, I emphasized on narrow in order processors and hardcoded dimensions like width, fetch speed, and scheduling. Unlike EDP, which randomly biases toward the lower half of each dimension, EDAP selectively targets values that minimize physical footprint. For ED2AP, I did not bias a single metric, instead I allowed all dimensions to be tunable which would allow a wide random exploration across all performance, area, and energy.
Results and Analysis
EDP
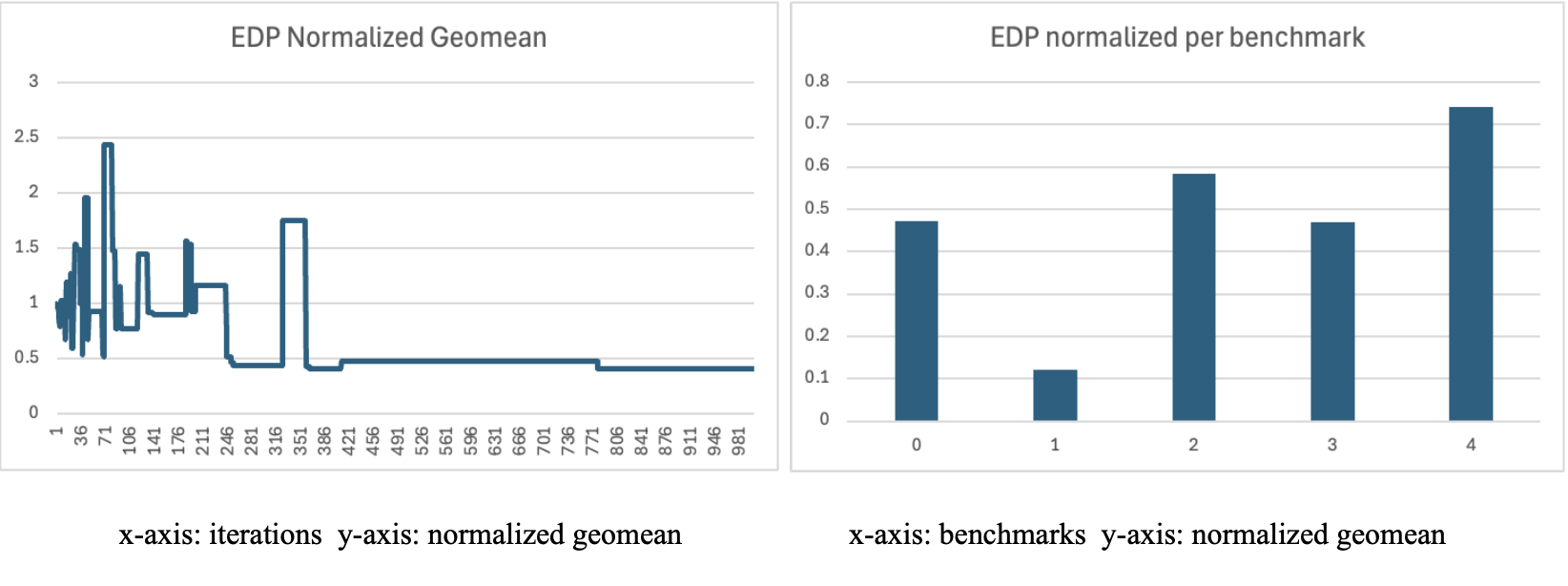
The early spike in the EDP plot shows the initial phase to explore inefficient configurations, but as more iterations were evaluated, the heuristic started to converge toward simpler and low energy efficient values. The best EDP configuration achieved the lowest value on benchmark 1 and the highest on benchmark 4.
ED2P
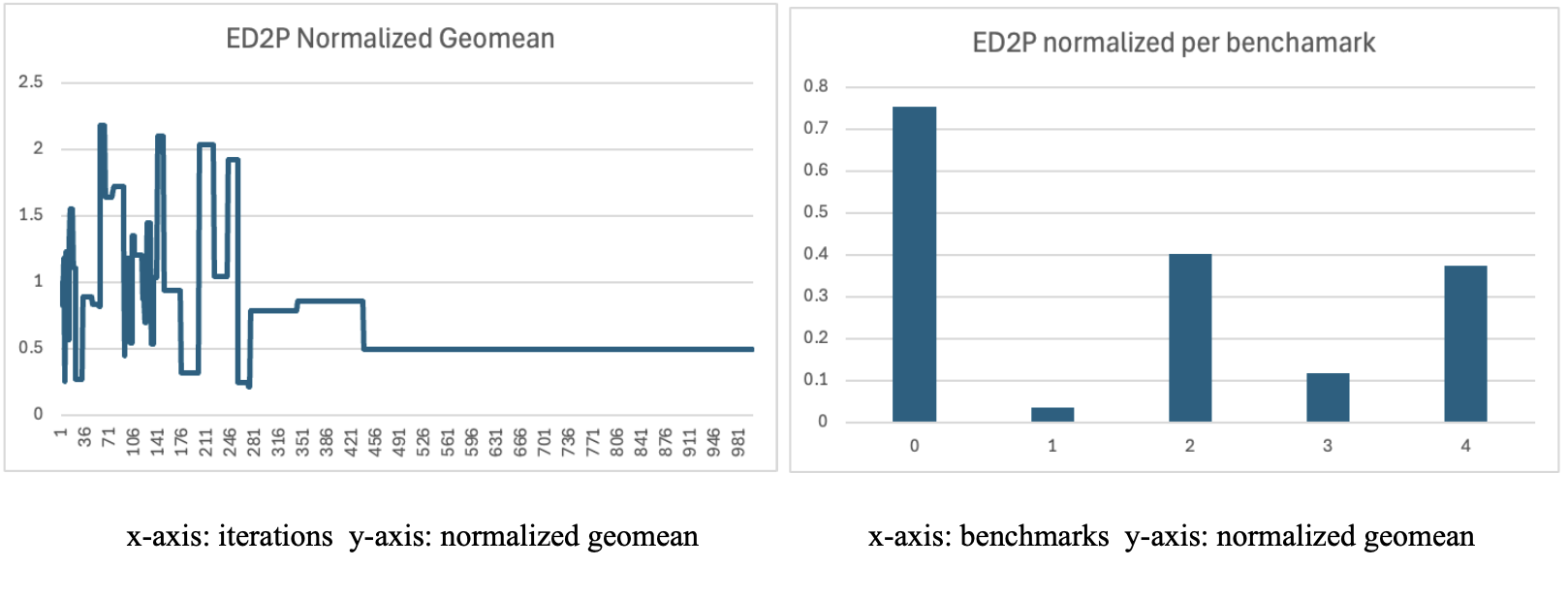
The early spike in the ED2P plot shows the initial phase to explore inefficient configuration, but as more iterations were evaluated, the heuristic started to converge toward high throughput designs. The best ED2P configuration prioritized a wider out of order processor achieving the lowest value on benchmark 1 and the highest on benchmark 0.
EDAP
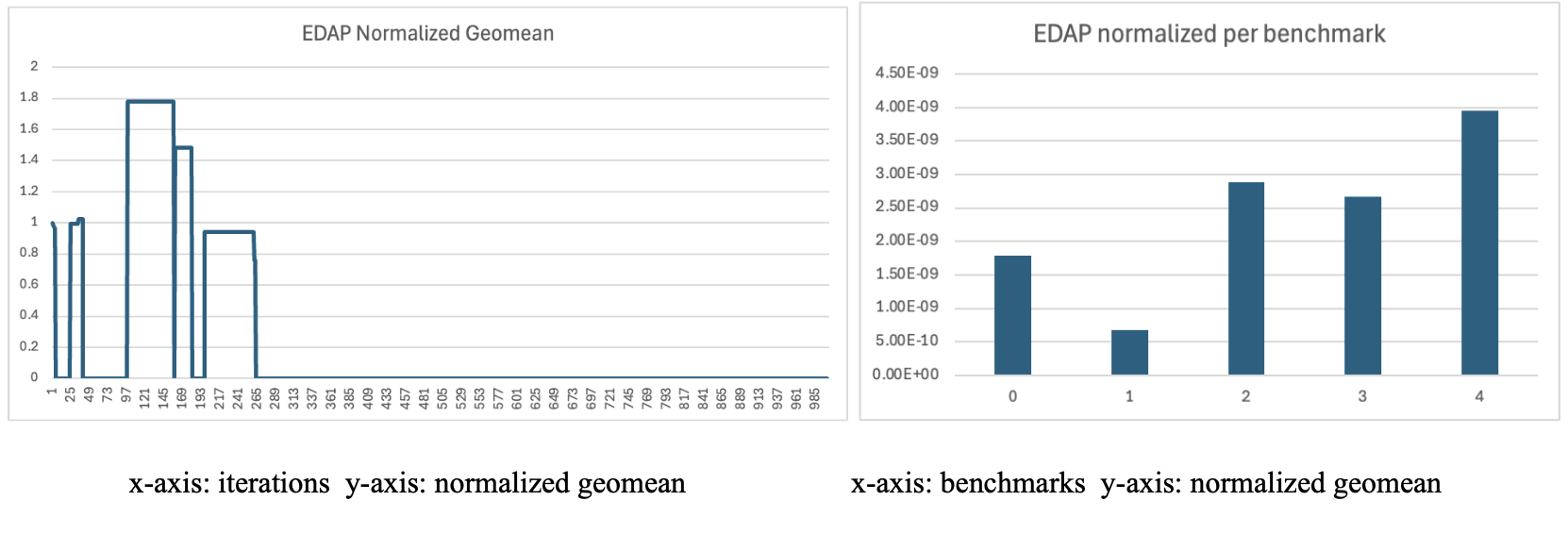
EDAP normalized geomean had a spiky start but as more iterations were evaluated, the heuristic started to converge toward a minimized EDAP around 1.07 × 10−8 J s mm2. The best EDAP configuration used a narrow in order processor and low indexed dimensions to minimize a physical footprint without a huge loss in performance. This configuration achieved the lowest value on benchmark 1 and the highest on benchmark 4.
ED2AP
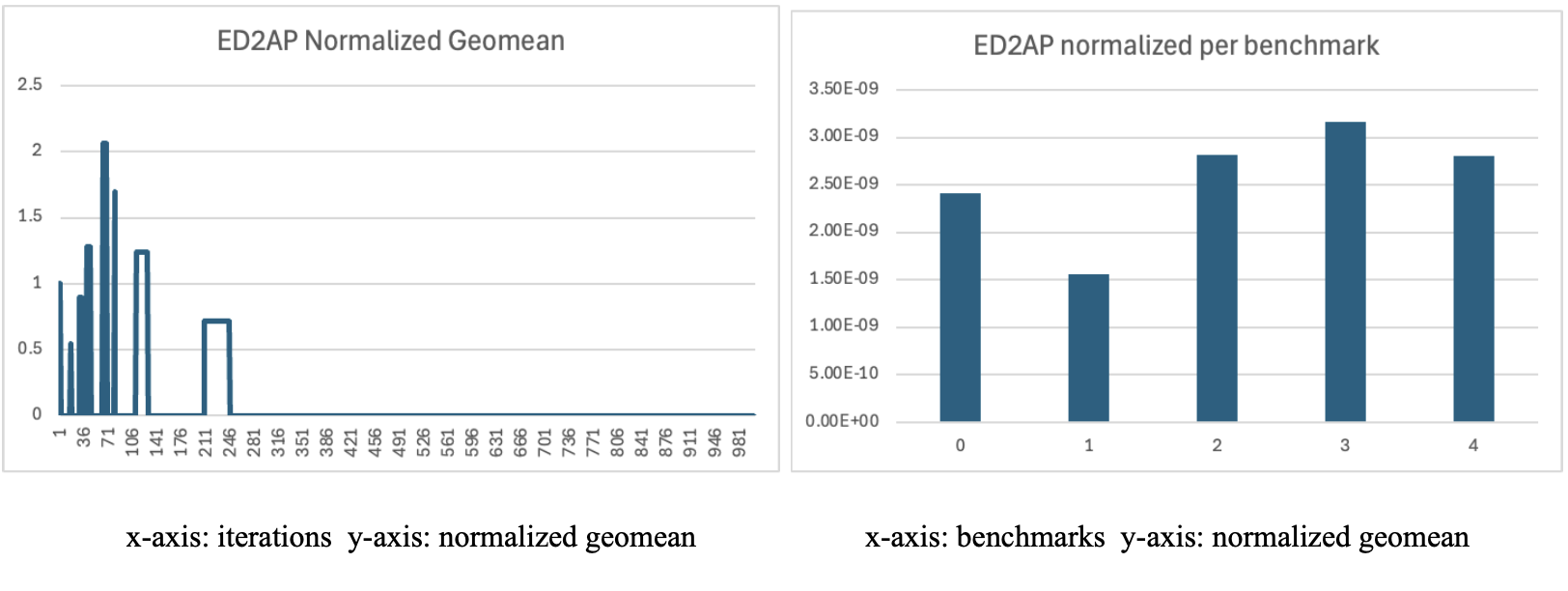
Similar to the other optimizations ED2AP, the normalized geomean had a spiky start but as more iterations were evaluated, the heuristic started to converge toward a minimized ED2AP around 1.87 × 10−8 J s2 mm2. The best ED2AP configuration which factors in energy, performance, and area resulted in a narrow in order processor with scattered HW configurations. It achieved the lowest value on benchmark 1 and the highest on benchmark 3.
All of the optimizations were normalized to the baseline (0, 0, 0, 0, 0, 0, 5, 0, 5, 0, 2, 2, 2, 3, 0, 0, 3, 0).
Best configurations
| Dim | EDP | ED2P | EDAP | ED2AP | Baseline |
|---|---|---|---|---|---|
| 0: Width | 2 | 4 | 1 | 1 | 1 |
| 1: Fetch speed | 2 | 2 | 2 | 2 | 1 |
| 2: Scheduling | out of order | out of order | in order | in order | in order |
| 3: RUU Size | 128 | 64 | 16 | 8 | 4 |
| 4: LSQ Size | 32 | 16 | 8 | 8 | 4 |
| 5: Memports | 1 | 2 | 2 | 1 | 1 |
| 6: L1D sets | 512 | 512 | 512 | 512 | 1024 |
| 7: L1D ways | 1 | 1 | 2 | 2 | 1 |
| 8: L1I sets | 1024 | 128 | 512 | 512 | 1024 |
| 9: L1I ways | 2 | 4 | 4 | 2 | 2 |
| 10: Unified L2 sets | 2048 | 256 | 512 | 512 | 1024 |
| 11: Unified L2 block size | 128 | 64 | 128 | 64 | 64 |
| 12: Unified L2 ways | 2 | 8 | 2 | 4 | 4 |
| 13: TLB sets | 16 | 8 | 16 | 64 | 32 |
| 14: L1D latency | 1 | 2 | 2 | 2 | 1 |
| 15: L1I latency | 4 | 4 | 4 | 2 | 1 |
| 16: Unified L2 latency | 8 | 8 | 6 | 7 | 8 |
| 17: Branch predictor | perfect | Bimodal | 2 level GAp | 2 Level GAp | perfect |
Conclusion
In this project, I explored a large space of processor configurations and designed heuristics for different optimization goals: EDP, EDAP, ED2P, and ED2AP. By exploiting architectural characteristics and tailoring the algorithm, I was able to find the “best” configuration across different optimizations. This project helped me better understand how microarchitectural choices affect performance, energy, and area in the real world systems.
Project Code
The proposal code (YOURCODEHERE-final.cpp) implements the heuristic search, generating candidate processor configurations and calling into 431project.cpp to evaluate them against benchmarks. It relies on 431projectUtils.cpp to decode indices and enforce architectural constraints, ensuring only valid configurations are tested, while the shared header file (431project.h) ties these components together. The full project also includes a Makefile to compile everything into a single executable and a worker.sh script to automate multiple runs and manage evaluation limits. Here, only the proposal code is shown, as it contains the core algorithm driving the exploration process. The results it produces — including best configurations and performance metrics — form the basis for the analysis and discussion presented on this site.
Show C++ source (toggle)
#include <iostream>
#include <sstream>
#include <stdio.h>
#include <stdlib.h>
#include <string>
#include <sys/stat.h>
#include <unistd.h>
#include <algorithm>
#include <fstream>
#include <map>
#include <math.h>
#include <fcntl.h>
#include "431project.h"
using namespace std;
/*
* Not all configurations are inherently valid. (For example, L1 > L2).
* Returns 1 if valid, else 0.
*/
int validateConfiguration(std::string configuration){
// is the configuration at least describing 18 integers/indices?
if (isan18dimconfiguration(configuration) != 1)
return 0;
// if it is, lets convert it to an array of ints for use below
int configurationDimsAsInts[18];
int returnValue = 1; // assume true, set 0 if otherwise
extractConfiguration(configuration, configurationDimsAsInts); // Configuration parameters now available in array
//
// FIXME - YOUR VERIFICATION CODE HERE
// ...
int widthV = 1 << configurationDimsAsInts[0];
int fetchspeedV = 1 << configurationDimsAsInts[1];
int schedulingV = configurationDimsAsInts[2];
int ruusizeV = 1 << (configurationDimsAsInts[3] + 2);
int lsqsizeV = 1 << (configurationDimsAsInts[4] + 2);
int memportV = 1 << configurationDimsAsInts[5];
int L1D_setsV = 32 << configurationDimsAsInts[6];
int L1D_waysV = 1 << configurationDimsAsInts[7];
int L1I_setsV = 32 << configurationDimsAsInts[8];
int L1I_waysV = 1 << configurationDimsAsInts[9];
//helpers
int L1_blksizeV = widthV * 8;
unsigned L1D_sizeV = L1D_setsV * L1D_waysV * L1_blksizeV;
unsigned L1I_sizeV = L1I_setsV * L1I_waysV * L1_blksizeV;
int L2_setsV = 256 << configurationDimsAsInts[10];
int L2_blksizeV = 16 << configurationDimsAsInts[11]; //bytes
int L2_waysV = 1 << configurationDimsAsInts[12];
unsigned L2_sizeV = L2_setsV * L2_blksizeV * L2_waysV;
int tlb_sets = 4 << configurationDimsAsInts[13];
int L1D_latency =configurationDimsAsInts[14] + 1;
int L1I_latency =configurationDimsAsInts[15] + 1;
int L2_latency =configurationDimsAsInts[16] + 5;
int bp = configurationDimsAsInts[17];
//basic limiters
if(widthV < 1|| fetchspeedV < 1 || schedulingV< 0 || ruusizeV < 4 || lsqsizeV < 4 || memportV <1 || L1D_setsV < 32 || L1D_waysV < 1
|| L1I_setsV < 32 || L1I_waysV < 1 || L2_setsV < 256 ||L2_blksizeV < 16 || L2_waysV < 1 || tlb_sets < 4 || L1D_latency < 1
|| L1I_latency < 1 || L2_latency < 5 ||bp < 0){
return 0;
}
if (widthV > 8|| fetchspeedV > 2 || schedulingV> 1 || ruusizeV > 128 || lsqsizeV > 32 || memportV >2 || L1D_setsV > 8192
|| L1D_waysV > 4 || L1I_setsV > 8192 || L1I_waysV > 4 || L2_setsV > 131072 ||L2_blksizeV > 128 || L2_waysV > 16 || tlb_sets > 64
|| L1D_latency > 7 || L1I_latency > 7 || L2_latency > 13 ||bp > 5){
return 0;
}
//L2 must be bigger than:
//both L1 caches
//twice as big as L1
else if(L2_sizeV < (L1D_sizeV + L1I_sizeV) || (L2_blksizeV < (2*L1_blksizeV ))){
return 0;
}
//L1D
int t = 0, n = 0;
if(L1D_sizeV == 8*1024){
t = 1;
}
else if(L1D_sizeV == 16*1024){
t = 2;
}
else if(L1D_sizeV == 32*1024){
t = 3;
}
else if(L1D_sizeV == 64*1024){
t = 4;
}
else{
return 0;
}
if(L1D_waysV == 2){
n = 1;
}
else if(L1D_waysV == 4){
n = 2;
}
if(L1D_latency != t + n){
return 0;
}
t = 0;
n = 0;
//L1I
if(L1I_sizeV == 8*1024){
t = 1;
}
else if(L1I_sizeV == 16*1024){
t = 2;
}
else if(L1I_sizeV == 32*1024){
t = 3;
}
else if(L1I_sizeV == 64*1024){
t = 4;
}
else{
return 0;
}
if(L1I_waysV == 2){
n = 1;
}
else if(L1I_waysV == 4){
n = 2;
}
if(L1I_latency != t + n){
return 0;
}
t = 0;
n = 0;
//L2
if(L2_sizeV == 128*1024){
t = 7;
}
else if(L2_sizeV == 256*1024){
t = 8;
}
else if(L2_sizeV == 512*1024){
t = 9;
}
else if(L2_sizeV == 1024*1024){
t = 10;
}
else if(L2_sizeV == 2048*1024){
t = 11;
}
else{
return 0;
}
if(L2_waysV == 1){
n = -2;
}
else if(L2_waysV == 2){
n = -1;
}
else if(L2_waysV == 4){
n = 0;
}
else if(L2_waysV == 8){
n = 1;
}
else if(L2_waysV == 16){
n = 2;
}
if(L2_latency != t + n){
return 0;
}
if(widthV > 2 * fetchspeedV || tlb_sets * 4 > 512){
return 0;
}
return returnValue;
}
/*
* Given the current best known configuration for a particular optimization,
* the current configuration, and using globally visible map of all previously
* investigated configurations, suggest a new, previously unexplored design
* point. You will only be allowed to investigate 1000 design points in a
* particular run, so choose wisely. Using the optimizeForX variables,
* propose your next configuration provided the optimiztion strategy.
*/
std::string YourProposalFunction(
std::string currentconfiguration,
std::string bestED2Pconfiguration,
std::string bestEDPconfiguration,
std::string bestEDAPconfiguration,
std::string bestED2APconfiguration,
int optimizeforED2P,
int optimizeforEDP,
int optimizeforEDAP,
int optimizeforED2AP
){
/*
* REPLACE THE BELOW CODE WITH YOUR PROPOSAL FUNCTION
*
* The proposal function below is extremely unintelligent and
* will produce configurations that, while properly formatted,
* violate specified project constraints
*/
// produces an essentially random proposal
int configuration[18];
extractConfiguration(currentconfiguration, configuration);
static int DIM_index = 0; // to remember value across different calls
int dimV = DIM_index;
DIM_index = (DIM_index + 1) %18; //rotates through each of the 18 dimensions
int validChoices = GLOB_dimensioncardinality[dimV];
//iteration 4
if(optimizeforED2P){
configuration[dimV] = (configuration[dimV] + 1) %validChoices;
configuration[0] = (rand() %2 ) + 2; // width being very large
configuration[1] = 1; //fetch speed
configuration[2] = 1; //scheduling OoO
}
else if(optimizeforEDP){
configuration[dimV] = (configuration[dimV] +(validChoices/2) - 1) %validChoices;
}
else if(optimizeforEDAP){
configuration[dimV] = (configuration[dimV] + 1) %validChoices;
configuration[0] = 0;
configuration[1] = 1; //fetch speed
configuration[2] = 0; //scheduling in order
//configuration[dimV] = (configuration[dimV] +(validChoices/2) - 1) %validChoices;
//iteration 5
//configuration[dimV] = rand()% (validChoices/ 2 + 1);
}
else if(optimizeforED2AP){
for(int dimV = 0; dimV < 18; dimV++){
configuration[dimV] = rand() % GLOB_dimensioncardinality[dimV];
}
}
else{
//not possible
}
//iteration 2
//generating neighbor
//configuration[dimV] = (configuration[dimV] + 1) %validChoices; // rotates through each of the index in specified dimension
string tempConfig = compactConfiguration(configuration);
//added this in my third iteration of my propossal function
if(validateConfiguration(tempConfig) == 0){
int retreatedConfiguration[18];
string newConfig = "";
while(true){
for(int i = 0; i < 18; i++){
retreatedConfiguration[i] = rand() % GLOB_dimensioncardinality[i];
}
newConfig = compactConfiguration(retreatedConfiguration);
if(validateConfiguration(newConfig)){ // if new random config passes
break;
}
}
tempConfig = newConfig;
}
return tempConfig;
}